Making Sense of How Whisper Processes Audio
I’ve been recently playing around with OpenAI’s Whisper, and I’ve also come to need to understand some of its internals. Specifically, I’m interested in how Whisper builds contextual representations of audio signals. Coming from the NLP domain, where transformers process “tokens” as their basic unit, understanding some numbers in play was not straightforward. I’m hence putting down my thoughts and comments, hoping that they will be helpful to somebody else and won’t annoy the audio experts out there too much.
Whisper is an encoder-decoder model where the encoder processes audio signals and produces a sequence of contextualized representations. The decoder processes text tokens, and while doing so, it cross-attends to the encoder-generated representations.
Since we are interested in the audio part, this blog will focus on Whisper’s encoder. In the audio domain, there’s an interplay of audio segments (also known as frames), sampling rate, and features from the frequency domain.
This blog will be code-oriented, i.e., I will use and point to code examples and lines to keep the conversation going. You can find a companion Google Colab on top. For this short journey, I’ll focus on Whisper’s large v3 model and some samples from Google’s FLEURS dataset.
Let’s get the first example from the training Italian split:
dataset = load_dataset("google/fleurs", "it_it", split="train", streaming=True)
row = next(iter(dataset))
row[“audio”] is composed as follows:
- N samples: 129600
- Sampling rate: 16000
I.e., these Pulse-code Modulation (PCM) samples correspond to 129600 / 16000 = 8.1 seconds of recording.
If we process the signal with HF’s AutoProcessor (which in turn uses the WhisperFeatureExtractor class) and ask it to return the attention mask (useful for, e.g., batched inference), i.e.,
inputs = processor(
row["audio"]["array"],
return_tensors="pt",
return_attention_mask=True,
sampling_rate=16000
)
we end up with the following:
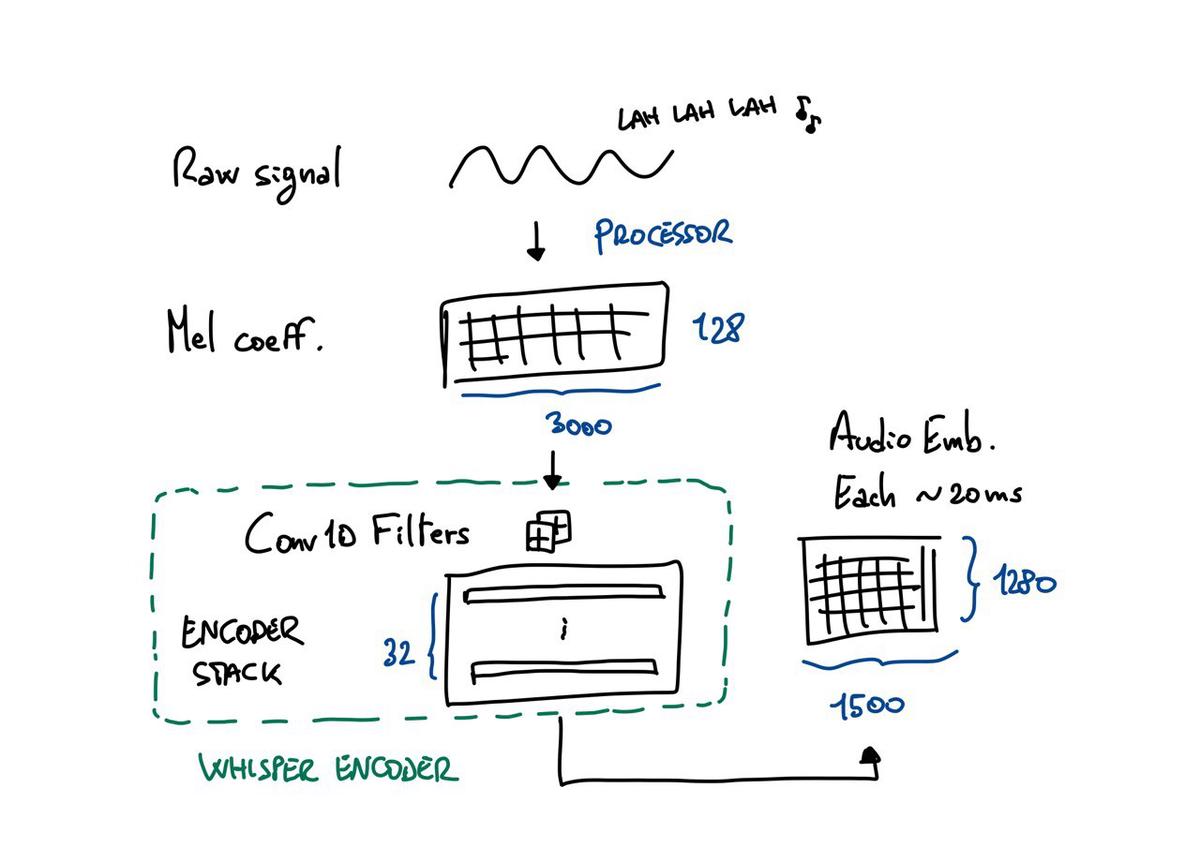
inputs["input_features"]of shape [1, 128, 3000]inputs["attention mask"]of shape [1, 3000] (0s for padding positions, 1s everywhere else)
Let’s make some sense out of it. Coming from the NLP domain and working with LMs, the standard shape format is (batch size, sequence length, hidden size), where the last dimension is typically the model’s hidden size to represent contextual embeddings internally. Here, the first and second dimensions are switched, i.e., we have 128 input features and 3000 input positions representing the audio context (i.e., the sequence length). The input features correspond to the log-magnitude Mel spectrogram representation of the input. The number of Mel bins is a design choice – you can find it under the name “num_mel_bins” in the config file. I believe the inverted position of features and sequence length is a design choice, too, mainly to align with where channel and sequence length dimensions are found in signal processing libraries – e.g., torch’s Conv1d module puts the channel in the second dimension.
From the preprocessor config file, we also know that the “chunk length” is 30. The naming convention is not ideal, but, here, we mean seconds, which is the length of recordings Whisper was trained on (see Section 2.1 from the paper). Since we have 3000 embeddings (or positions) representing 30 seconds, we know we “created” an embedding every 30 / 3000 = 0.01 seconds or ten milliseconds. As per the authors' design, input embeddings are constructed with a sliding window of 25 milliseconds and 10 milliseconds of stride. In summary, each embedding encodes 25 ms of signal, and the first 15 are also used to build the trailing embedding (except for the first position). For reference, vowel-related phonemes in Italian range from 50 to 200 ms. Moreover, depending on the use case, a context (or chunk length) of 30 seconds requires some considerations. If the average input duration is significantly shorter, a 30s context is inefficient, as many embeddings will represent padding (for reference, the mean duration in the Italian splits of Mozilla Common Voice, FLEURS, and VoxPopuli is 6, 13, and 12 seconds, respectively). If inputs are longer than 30s, you must trim or split them in different segments.
Back to our example. If we have 8.1s of audio, we will have approximately 8.1 / 0.01 = 810 embeddings of actual context, and the rest is padding. You can verify that by running:
inputs["attention_mask"].sum().item() # the output is 810
Or by checking what inputs["input_features"][0, :, 811] or inputs["input_features"][0, :, 812] contain. You will notice they all have the same feature (remember, it’s 128 Mel features). The fact that they are all the same suggests that those positions in the audio domain had all the same value (likely the padding value, which is 0 for Whisper). As a further check, we can assume that the first 10 ms of the record also contain silence (i.e., a PCM value of 0 in the audio domain). Indeed, if we check what inputs["input_features"][0, :, 0] contains, we’ll find the same set of features of, for instance, inputs["input_features"][0, :, 812].
Let’s now move to inference. We know that Whisper has a maximum context length of 1500, which we can see from the model’s config file. This setting means the output will contain a maximum sequence length of 1500, whatever we produce. When the input is 3000 frames, the output of the encoder will have 1500 embeddings.
But how do we go from 3000 to 1500? This is due mainly to the second 1D convolutional filter. Roughly, the filter uses a kernel size=3 and stride=2, which turns a 3000-long sequence into a 1500-long one (see the detailed formula in torch’s docs). This transformation also means that each embedding represents 25*2 = 50 (overlapping) milliseconds in the audio domain.
Let’s do the last step and run the actual inference.
output = model.model.encoder(**inputs.to(device="cuda", dtype=torch.bfloat16), output_hidden_states=True)
The output_hidden_states=True parameter makes the code return the contextual representations the transformer encoder built when processing the input.
We can see that the output is comprised of:
output.last_hidden_state.shape # of shape torch.Size([1, 1500, 1280])
output.hidden_states # tuple of 33 elements (1 embedding layer + 32 encoder blocks)
Where 1500 is the sequence length we expected, and 1280 is the hidden size Whisper uses internally (you can retrieve this number from the model’s config).
That result wraps it up! Whisper has become a one-stop solution for many speech-related applications. I hope the posts have cleared some doubts about interpreting the model’s output and internals and will stem exciting research ideas.
Cheers
Acknowledgments
Thanks to Marco Gaido for the thorough revision.